Memory Interfaces
Beethoven provides abstractions for accessing both off-chip DRAM and on-chip memory. Choose the interface based on your access pattern and performance requirements.
- Overview
- Alignment Requirements
- Read Channels
- Write Channels
- Scratchpads
- User-Managed Memory
- Inter-Core Communication
- Performance Tuning
- API Reference
Interface Comparison
| Interface | Location | Auto DMA | Use Case |
|---|---|---|---|
| ReadChannelConfig | Off-chip DRAM | Yes | Stream data from external memory with automatic prefetching |
| WriteChannelConfig | Off-chip DRAM | Yes | Stream data to external memory with write buffering |
| ScratchpadConfig | On-chip BRAM/URAM | Yes | Buffering with automatic DMA init/writeback |
| Memory | On-chip BRAM/URAM/SRAM | No | Manual control, ASIC memory compiler integration |
| IntraCoreMemoryPorts | On-chip | N/A | Direct core-to-core communication without DRAM |
Quick Start
For streaming from DRAM: Use ReadChannelConfig for reads and WriteChannelConfig for writes. These provide automatic transaction management and high throughput.
For on-chip buffers: Use ScratchpadConfig if you need to initialize from or writeback to DRAM. Use Memory for manual control or ASIC designs.
For multi-core designs: Use IntraCoreMemoryPorts to pass data between cores without going through external memory.
Alignment Requirements
All memory transactions in Beethoven must be properly aligned to avoid data corruption and runtime errors. This is a fundamental hardware requirement, not a software convenience.
Core Rules
Rule 1: Address Alignment
- All memory addresses (read, write, scratchpad init/writeback) must be aligned to
dataBytes - Formula:
address % dataBytes == 0
Rule 2: Length Alignment
- All transaction lengths must be aligned to
dataBytes - Formula:
length % dataBytes == 0
Rule 3: Applies to All Channels
- Read channels (
ReadChannelConfig) - Write channels (
WriteChannelConfig) - Scratchpad init/writeback operations (
ScratchpadConfig)
Misaligned addresses or lengths will cause silent data corruption or runtime crashes. The hardware will not detect or report alignment violations.
Examples
Valid Alignments (4-byte channel, dataBytes = 4):
// ✅ Correct - address aligned to 4 bytes
uint32_t* data = allocate(1024); // Returns 4-byte aligned address
auto resp = myCore::read(0, (remote_ptr)data, 1024); // length=1024 is 4-byte aligned
Valid Alignments (64-byte channel, dataBytes = 64):
// ✅ Correct - both address and length aligned to 64 bytes
void* buffer = aligned_alloc(64, 4096); // 64-byte aligned address
auto resp = myCore::dma_read(0, (remote_ptr)buffer, 4096); // length=4096 is 64-byte aligned
Invalid Alignments:
// ❌ WRONG - address not aligned (4-byte channel)
auto resp = myCore::read(0, 0x1002, 1024); // 0x1002 % 4 != 0
// ❌ WRONG - length not aligned (4-byte channel)
auto resp = myCore::read(0, 0x1000, 1023); // 1023 % 4 != 0
// ❌ WRONG - both misaligned (64-byte channel)
auto resp = myCore::read(0, 0x1040, 4100); // 0x1040 % 64 != 0, 4100 % 64 != 0
Quick Reference: Checking Alignment
In Hardware (Scala/Chisel):
// Check if address is aligned to dataBytes
val is_aligned = (addr % dataBytes.U) === 0.U
// Common dataBytes values and their alignment
// dataBytes = 4 → addresses must be multiples of 4 (0x0, 0x4, 0x8, ...)
// dataBytes = 8 → addresses must be multiples of 8 (0x0, 0x8, 0x10, ...)
// dataBytes = 64 → addresses must be multiples of 64 (0x0, 0x40, 0x80, ...)
In Software (C++):
// Ensure aligned allocation
void* buffer = aligned_alloc(dataBytes, total_size);
// Check alignment at runtime
assert((uintptr_t)buffer % dataBytes == 0);
assert(transaction_length % dataBytes == 0);
Why Alignment Matters
Hardware Requirement:
- Memory controllers and AXI fabric require aligned transactions for correct operation
- Unaligned accesses may be split into multiple sub-transactions with undefined behavior
- Width conversion logic assumes aligned boundaries
Performance Impact:
- Misaligned transactions can cause significant performance degradation
- May trigger exceptions or stalls in the memory subsystem
Consequences of Misalignment
| Issue | Symptom |
|---|---|
| Silent Data Corruption | Wrong data read/written without error messages |
| Runtime Crashes | Segmentation faults or bus errors on FPGA |
| Simulation Mismatches | Works in simulation but fails on hardware |
| Undefined Behavior | Unpredictable results, non-deterministic failures |
Debugging Alignment Issues
If you suspect alignment problems:
-
Check your addresses:
printf("Address: 0x%lx, aligned: %s\n", addr,
(addr % dataBytes == 0) ? "YES" : "NO"); -
Check your lengths:
printf("Length: %zu, aligned: %s\n", len,
(len % dataBytes == 0) ? "YES" : "NO"); -
Review allocations: Ensure you're using
aligned_alloc()or platform-specific aligned allocation -
Check calculations: Address arithmetic (e.g.,
base + offset) may produce misaligned results
See the Debugging Guide for more troubleshooting steps.
Platform-Specific Notes
AWS F2:
- Typical
dataBytes: 64 (512-bit memory interface) - Use
aligned_alloc(64, size)for allocations
Kria/Zynq:
- Typical
dataBytes: 4-8 (32-64 bit interfaces) - Shared memory with ARM may have stricter requirements
Simulation:
- DRAMsim3 enforces alignment requirements
- Test alignment compliance in simulation before FPGA deployment
See Also
- Read Channels - Request channel alignment requirements
- Write Channels - Data channel alignment requirements
- Debugging Guide - Troubleshooting misalignment errors
Read Channels
Read channels stream data from external DRAM with automatic prefetching and transaction management.
Configuration
case class ReadChannelConfig(
name: String, // Unique identifier
dataBytes: Int, // Channel width in bytes (power of 2)
nChannels: Int = 1, // Number of parallel channels
maxInFlightTxs: Option[Int] = None, // Max concurrent transactions
bufferSizeBytesMin: Option[Int] = None // Minimum prefetch buffer size
)
Parameters:
name: Unique identifier within the accelerator coredataBytes: Physical data bus width in bytes. All transactions must be aligned to this width.nChannels: Number of parallel request/data channel pairs with the same namemaxInFlightTxs: Controls throughput by allowing multiple concurrent memory transactions (see Performance Tuning)bufferSizeBytesMin: Minimum size of internal prefetch buffer. Increase for bursty workloads.
Beethoven initializes maxInFlightTxs to platform-specific defaults. Increase it for higher throughput, but larger values may impact timing closure.
Core Interface
// Fetch the reader channel
def getReaderModule(name: String, idx: Int = 0): ReaderModuleChannel
case class ReaderModuleChannel(
requestChannel: DecoupledIO[ChannelTransactionBundle],
dataChannel: DataChannelIO
)
Request Channel (launch a transaction):
requestChannel.valid(Input): Drive high to start a new transactionrequestChannel.ready(Output): High when reader is ready for a new transactionrequestChannel.bits.address(Input): Starting address (aligned todataBytes)requestChannel.bits.len(Input): Transaction length in bytes (aligned todataBytes)
Misaligned addresses or lengths will cause silent data corruption or runtime crashes. Always align both address and length to dataBytes.
Data Channel (receive data):
dataChannel.inProgress(Output): High while transaction is activedataChannel.data.valid(Output): High when data is availabledataChannel.data.ready(Input): Drive high to consume datadataChannel.data.bits(Output): The requested data
Usage Example
// Configuration
memoryChannelConfig = List(
ReadChannelConfig("vec_a", dataBytes = 4),
ReadChannelConfig("vec_b", dataBytes = 4)
)
// In core implementation
val vec_a_reader = getReaderModule("vec_a")
// Launch read transaction
vec_a_reader.requestChannel.valid := start_read
vec_a_reader.requestChannel.bits.addr := base_addr
vec_a_reader.requestChannel.bits.len := num_bytes
// Consume data
my_module.io.input <> vec_a_reader.dataChannel.data
Transaction Waveform
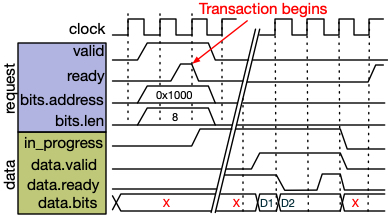
The request channel exchanges a handshake with address/length payloads. After indeterminate latency, data arrives. Data advances only when both valid and ready are high.
Write Channels
Write channels stream data to external DRAM with automatic write buffering.
Configuration
case class WriteChannelConfig(
name: String, // Unique identifier
dataBytes: Int, // Channel width in bytes (power of 2)
nChannels: Int = 1, // Number of parallel channels
maxInFlightTxs: Option[Int] = None, // Max concurrent transactions
bufferSizeBytesMin: Option[Int] = None // Minimum write buffer size
)
Configuration parameters are identical to ReadChannelConfig.
Core Interface
// Fetch the writer channel
def getWriterModule(name: String, idx: Int = 0): WriterModuleChannel
case class WriterModuleChannel(
requestChannel: DecoupledIO[ChannelTransactionBundle],
dataChannel: WriterDataChannelIO
)
Request Channel: Same as read channels.
Data Channel (send data):
dataChannel.isFlushed(Output): High when all writes have completeddataChannel.data.valid(Input): Drive high to writedata.bitsto memorydataChannel.data.ready(Output): High when writer can accept datadataChannel.data.bits(Input): The data to write
Writes complete asynchronously. Use isFlushed to detect when all writes have been acknowledged by memory.
Usage Example
// Configuration
memoryChannelConfig = List(
WriteChannelConfig("vec_out", dataBytes = 4)
)
// In core implementation
val vec_out_writer = getWriterModule("vec_out")
// Launch write transaction
vec_out_writer.requestChannel.valid := start_write
vec_out_writer.requestChannel.bits.addr := output_addr
vec_out_writer.requestChannel.bits.len := num_bytes
// Send data
vec_out_writer.dataChannel.data.valid := my_module.io.output.valid
vec_out_writer.dataChannel.data.bits := my_module.io.output.bits
my_module.io.output.ready := vec_out_writer.dataChannel.data.ready
// Wait for completion
when (vec_out_writer.dataChannel.isFlushed) {
state := s_done
}
Scratchpads
Scratchpads provide managed on-chip memory with automatic DMA initialization and writeback capabilities.
Configuration
case class ScratchpadConfig(
name: String, // Unique identifier
dataWidthBits: Int, // Bit-level granularity
nDatas: Int, // Number of rows
nPorts: Int, // Read-write ports (max 2 recommended)
latency: Number = 2, // Read latency in cycles
features: ScratchpadFeatures = ScratchpadFeatures()
)
case class ScratchpadFeatures(
readOnly: Boolean = false, // Read-only mode
supportWriteback: Boolean = false, // Enable writeback to DRAM
supportMemRequest: Boolean = true, // Enable init from DRAM
specialization: ScratchpadSpecialization, // Data packing strategy
nBanks: Int = 1, // Banking for deep memories
writeEnableMuxing: Boolean = false // Byte-wise write enable
)
Parameters:
name: Unique identifier forgetScratchpad()dataWidthBits: Bit-width of each datum (unlike byte-level precision of read/write channels)nDatas: Number of rows in the memory arraynPorts: Number of read-write ports (maximum 2 recommended for BRAM/URAM mapping)latency: Read latency. FPGA memories can cascade for larger sizes at cost of latency.
Features:
readOnly: Enables Simple-Dual-Port BRAM mode (one read port, init writes only)supportWriteback: Adds DMA engine to writeback scratchpad contents to DRAMsupportMemRequest: Allows initializing scratchpad from DRAM (default: enabled)specialization:flatPacked(default): For power-of-2 byte-aligned data widthsPackedSubword: For non-byte-aligned data (e.g., 17-bit values) with minimal overhead
nBanks: Stripe data across multiple BRAMs for deep, narrow memorieswriteEnableMuxing: Enable byte-wise write enable
For efficient BRAM mapping, use nPorts = 2. Higher port counts may require registers or URAM.
Core Interface
def getScratchpad(name: String): ScratchpadModuleChannel
case class ScratchpadModuleChannel(
requestChannel: ScratchpadMemReqPort, // Init and writeback
dataChannels: Seq[ScratchpadDataPort] // User access ports
)
Request Channel (DMA operations):
class ScratchpadMemReqPort extends Bundle {
val init = Flipped(Decoupled(new Bundle {
val memAddr = Address() // DRAM source address
val scAddr = UInt(...) // Scratchpad starting index
val len = UInt(...) // Number of bytes to transfer
}))
val writeback = Flipped(Decoupled(new Bundle {
val memAddr = Address() // DRAM destination address
val scAddr = UInt(...) // Scratchpad starting index
val len = UInt(...) // Number of bytes to transfer
}))
}
Data Ports (user access):
class ScratchpadDataPort extends Bundle {
val req = Flipped(Decoupled(new Bundle {
val addr = UInt(...) // Scratchpad index
val data = UInt(...) // Data to write (if writing)
val write_enable = Bool() // Active-high write enable
}))
val res = ValidIO(UInt(...)) // Read result (latency cycles later)
}
Usage Example
// Configuration
memoryChannelConfig = List(
ScratchpadConfig(
name = "buffer",
dataWidthBits = 32,
nDatas = 1024,
nPorts = 2,
features = ScratchpadFeatures(
supportMemRequest = true,
supportWriteback = true
)
)
)
// In core implementation
val sp = getScratchpad("buffer")
// Initialize from DRAM
sp.requestChannel.init.valid := start_init
sp.requestChannel.init.bits.memAddr := src_addr
sp.requestChannel.init.bits.scAddr := 0.U
sp.requestChannel.init.bits.len := num_bytes
// Wait for init completion
when (sp.requestChannel.init.ready) {
state := s_processing
}
:::warning[Init Completion]
Init completion is signaled by `requestChannel.init.ready` going high, NOT by a separate done signal. Check `.ready` to confirm DMA transfer is complete.
:::
// Read from scratchpad (port 0)
val port_a = sp.dataChannels(0)
port_a.req.valid := read_valid
port_a.req.bits.addr := read_idx
port_a.req.bits.write_enable := false.B
// Result arrives 'latency' cycles later
when (port_a.res.valid) {
val data = port_a.res.bits
// Process data
}
// Write to scratchpad (port 1)
val port_b = sp.dataChannels(1)
port_b.req.valid := write_valid
port_b.req.bits.addr := write_idx
port_b.req.bits.data := write_data
port_b.req.bits.write_enable := true.B
// Writeback to DRAM
sp.requestChannel.writeback.valid := start_writeback
sp.requestChannel.writeback.bits.memAddr := dest_addr
sp.requestChannel.writeback.bits.scAddr := 0.U
sp.requestChannel.writeback.bits.len := num_bytes
Init and writeback operations lock one data port. Plan state machines accordingly.
User-Managed Memory
For direct control over on-chip memory cells, use the Memory interface. On FPGA, this instantiates vendor templates (BRAM/URAM). On ASIC, it interfaces with the memory compiler.
Instantiation
Memory(
latency: Int, // Read latency
dataWidth: Int, // Bit width
nRows: Int, // Number of rows
nReadPorts: Int, // Read-only ports
nWritePorts: Int, // Write-only ports
nReadWritePorts: Int, // Read-write ports
withWriteEnable: Boolean = false, // Byte-wise write enable
debugName: Option[String] = None, // Name in RTL
allowFallbackToRegister: Boolean = true
)
Parameters:
latency: Read latency in cycles. ASIC targets cascade cells for higher latency (see ASIC Memory Compiler)dataWidth: Bit-width of memorynRows: Number of rowsnReadPorts,nWritePorts,nReadWritePorts: Port counts. FPGA supports Simple-Dual-Port (read + write) efficiently.withWriteEnable: Enable byte-wise write masking (default: global write enable)debugName: Optional name for RTL annotationallowFallbackToRegister: Fallback to registers if configuration unsupported (default: true)
Memory IO Bundle
class MemoryIOBundle extends Bundle {
val addr = Input(Vec(nPorts, UInt(addrBits.W)))
val data_in = Input(Vec(nPorts, UInt(dataWidth.W)))
val data_out = Output(Vec(nPorts, UInt(dataWidth.W)))
val chip_select = Input(Vec(nPorts, Bool()))
val read_enable = Input(Vec(nPorts, Bool()))
val write_enable = Input(Vec(nPorts, ...)) // Bool or UInt based on withWriteEnable
val clock = Input(Bool())
def getReadPortIdx(idx: Int): Int
def getWritePortIdx(idx: Int): Int
def getReadWritePortIdx(idx: Int): Int
def initLow(clock: Clock): Unit
}
All input signals are active-high, even if the underlying memory uses active-low control. Beethoven handles polarity conversion.
Usage Example
val my_memory = Memory(
latency = 2,
dataWidth = 32,
nRows = 1024,
nReadPorts = 1,
nWritePorts = 1,
nReadWritePorts = 0,
debugName = Some("my_buffer")
)
// Initialize all signals to inactive
my_memory.initLow(clock)
// Get port indices
val read_port = my_memory.getReadPortIdx(0)
val write_port = my_memory.getWritePortIdx(0)
// Read operation (latency = 2 cycles)
my_memory.chip_select(read_port) := true.B
my_memory.read_enable(read_port) := true.B
my_memory.addr(read_port) := read_addr
// Result available 2 cycles later:
val read_data = my_memory.data_out(read_port)
// Write operation (always 1 cycle)
my_memory.chip_select(write_port) := true.B
my_memory.write_enable(write_port) := true.B
my_memory.addr(write_port) := write_addr
my_memory.data_in(write_port) := write_data
Platform Differences
FPGA:
- Maps to BRAM (Simple Dual Port or True Dual Port) or URAM
- 2 ports recommended for efficient mapping
- Latency typically 1 or 2 cycles
ASIC:
- Interfaces with foundry memory compiler
- Supports cascading for higher latencies
- See ASIC Memory Compiler for details
Inter-Core Communication
For multi-core designs, IntraCoreMemoryPorts enable direct core-to-core data transfer without going through external DRAM.
Use Cases
- Producer-consumer pipelines
- Systolic arrays with data forwarding
- Heterogeneous accelerator systems
- Reducing DRAM bandwidth consumption
Configuration
Receiver (IntraCoreMemoryPortInConfig):
case class IntraCoreMemoryPortInConfig(
name: String,
nChannels: Int, // Number of channels
portsPerChannel: Int, // Ports per channel
dataWidthBits: Int, // Must be power-of-2 bytes
nDatas: Int, // Scratchpad depth
communicationDegree: CommunicationDegree,
readOnly: Boolean = false,
latency: Number = 2
)
Communication Degrees:
PointToPoint: One sender core to one receiver channelBroadcastAllCores: One channel broadcasts to all receiver coresBroadcastAllChannels: One sender core broadcasts to all receiver channels
Sender (IntraCoreMemoryPortOutConfig):
case class IntraCoreMemoryPortOutConfig(
name: String,
toSystem: String, // Target core name
toMemoryPort: String, // Target port name
nChannels: Int = 1
)
Multi-Core Example
// Producer core configuration
AcceleratorSystemConfig(
name = "Producer",
moduleConstructor = ModuleBuilder(p => new ProducerCore()(p)),
memoryChannelConfig = List(
IntraCoreMemoryPortOutConfig(
name = "output_stream",
toSystem = "Consumer",
toMemoryPort = "input_stream",
nChannels = 1
)
),
canSendDataTo = Seq("Consumer")
)
// Consumer core configuration
AcceleratorSystemConfig(
name = "Consumer",
moduleConstructor = ModuleBuilder(p => new ConsumerCore()(p)),
memoryChannelConfig = List(
IntraCoreMemoryPortInConfig(
name = "input_stream",
nChannels = 1,
portsPerChannel = 2,
dataWidthBits = 32,
nDatas = 256,
communicationDegree = CommunicationDegree.PointToPoint
)
)
)
Core Implementation
Consumer Core (receiver):
class ConsumerCore()(implicit p: Parameters) extends AcceleratorModule {
val input_ports = getIntraCoreMemIns("input_stream")
val port = input_ports(0)(0) // channel 0, port 0
// Read from incoming scratchpad
port.req.valid := read_enable
port.req.bits.addr := read_idx
port.req.bits.write_enable := false.B
// Result arrives after 'latency' cycles
when (port.res.valid) {
val data = port.res.bits
// Process incoming data
}
}
Producer Core (sender): Producer writes to consumer's scratchpad using RoCC commands with appropriate addressing. See Cross-Core Communication for details.
Benefits
- Low latency: On-chip communication bypasses DRAM
- Reduced bandwidth: No external memory traffic
- Flexibility: Configurable topologies for different architectures
Performance Tuning
Transaction Parallelism
Beethoven saturates memory bandwidth by issuing multiple concurrent transactions per logical read/write.
How it works:
- Large logical transactions (e.g., read 1GB) are broken into 4KB AXI bursts (page boundary limit)
- Multiple bursts are issued concurrently using different AXI IDs
- Each AXI ID maintains in-order execution, but different IDs can execute out-of-order
- This exploits DRAM bank-level parallelism for higher throughput
Tuning maxInFlightTxs:
- Controls how many 4KB transactions can be in-flight simultaneously
- Default: Platform-specific (typically 4-8)
- Increase for streaming workloads with high sustained bandwidth
- Decrease for bursty workloads or to reduce resource usage
- Trade-off: Higher values improve throughput but may impact timing closure
ReadChannelConfig(
name = "high_bandwidth_stream",
dataBytes = 64,
maxInFlightTxs = Some(16) // More parallelism for high throughput
)
Buffer Sizing
Prefetch Buffer (bufferSizeBytesMin):
- Controls internal buffer size for read channels
- Default: Based on
maxInFlightTxsand max transaction size - Increase for bursty workloads with brief high-throughput intervals
- Allows absorbing latency spikes without stalling
ReadChannelConfig(
name = "bursty_reader",
dataBytes = 8,
maxInFlightTxs = Some(4), // Lower for average case
bufferSizeBytesMin = Some(16384) // Large buffer for bursts
)
Write Buffer (bufferSizeBytesMin):
- Similar to read buffers, absorbs bursty writes
- Allows core to continue without waiting for DRAM acknowledgment
Width Conversion
Beethoven automatically handles channel width mismatches with platform fabric.
Channel Width < Fabric Width:
- Multiple channel transactions packed into wider fabric transactions
- Example: 4-byte channel on 64-byte fabric → 16 channel words per fabric word
- Alignment: Channel transactions must align to
dataBytes
Channel Width > Fabric Width:
- Single channel transaction unpacked across multiple fabric transactions
- Example: 64-byte channel on 8-byte fabric → 8 fabric transactions per channel word
Alignment Requirements:
- All addresses and lengths must be aligned to
dataBytes - Misaligned transactions will cause runtime errors
Platform Characteristics
AWS F2:
- Single DDR4 channel
- High bandwidth: ~17 GB/s theoretical
- Default
maxInFlightTxs: 8
Kria KV260:
- Shared DDR4 with ARM cores
- Available bandwidth: ~5-10 GB/s (shared with PS)
- Default
maxInFlightTxs: 4
ASIC:
- Highly platform-dependent
- Memory compiler parameters affect timing
- See ASIC Memory Compiler
API Quick Reference
Accessor Functions
Read Channels:
def getReaderModule(name: String, idx: Int = 0): ReaderModuleChannel
def getReaderModules(name: String): Seq[ReaderModuleChannel]
Write Channels:
def getWriterModule(name: String, idx: Int = 0): WriterModuleChannel
def getWriterModules(name: String): Seq[WriterModuleChannel]
Scratchpads:
def getScratchpad(name: String): ScratchpadModuleChannel
Inter-Core Memory:
def getIntraCoreMemIns(name: String): Seq[Seq[ScratchpadDataPort]]
User-Managed Memory:
Memory(
latency: Int,
dataWidth: Int,
nRows: Int,
nReadPorts: Int,
nWritePorts: Int,
nReadWritePorts: Int,
withWriteEnable: Boolean = false,
debugName: Option[String] = None,
allowFallbackToRegister: Boolean = true
): MemoryIOBundle
Bundle Types
ReaderModuleChannel:
case class ReaderModuleChannel(
requestChannel: DecoupledIO[ChannelTransactionBundle],
dataChannel: DataChannelIO
)
WriterModuleChannel:
case class WriterModuleChannel(
requestChannel: DecoupledIO[ChannelTransactionBundle],
dataChannel: WriterDataChannelIO // Includes isFlushed signal
)
ScratchpadModuleChannel:
case class ScratchpadModuleChannel(
requestChannel: ScratchpadMemReqPort, // init and writeback
dataChannels: Seq[ScratchpadDataPort] // nPorts elements
)
Signal Reference
ChannelTransactionBundle:
address: UInt- Starting byte addresslen: UInt- Length in bytes
DataChannelIO (Read):
inProgress: Bool(Output) - Transaction activedata.valid: Bool(Output) - Data availabledata.ready: Bool(Input) - Consumer readydata.bits: UInt(Output) - Data payload
WriterDataChannelIO:
isFlushed: Bool(Output) - All writes completeddata.valid: Bool(Input) - Write requestdata.ready: Bool(Output) - Writer readydata.bits: UInt(Input) - Data to write
ScratchpadDataPort:
req.valid: Bool(Input) - Request validreq.ready: Bool(Output) - Port availablereq.bits.addr: UInt(Input) - Scratchpad indexreq.bits.data: UInt(Input) - Write datareq.bits.write_enable: Bool(Input) - Write vs readres.valid: Bool(Output) - Read result valid (latency cycles after request)res.bits: UInt(Output) - Read data
MemoryIOBundle:
addr: Vec[UInt](Input) - Address per portdata_in: Vec[UInt](Input) - Write data per portdata_out: Vec[UInt](Output) - Read data per portchip_select: Vec[Bool](Input) - Active-high chip selectread_enable: Vec[Bool](Input) - Active-high read enablewrite_enable: Vec[...](Input) - Write enable (Bool or UInt based on config)
Default Values
Platform-Specific:
maxInFlightTxs: 4-8 (depends on platform)- Scratchpad
latency: 2 cycles (FPGA BRAM default) - Memory compiler latency: Platform-specific (ASIC)